Windows10内核池管理机制与利用方法
翻译自这篇文章,加了点自己的理解.
堆溢出漏洞是比较常见的一种漏洞类型,该类漏洞的利用需要深入了解windows堆的管理机制.
在windows系统中,池是内核层的堆空间,池分配器与用户层的分配是不同的,在windows 10 19h1更新以后,一些用户态使用的分段堆技术已被引入内核.
整体结构
1.池的内部结构
在内核中,池的分配和释放主要是通过两个函数,分别是ExAllocatePoolWithTag和ExFreePoolWithTag
1 | void * ExAllocatePoolWithTag ( POOL_TYPE PoolType , |
1 | void ExFreePoolWithTag ( void * P, |
其中ExAllocatePoolWithTag函数中的参数POOL_TYPE是一个位的字段,枚举值如下.
1 | typedef enum _POOL_TYPE { |
PoolType可以存储以下信息:
要申请的内存类型:NonPagedPool,PagedPool,SessionPool,NonPagedPoolNx
指定必须分配成功,否则触发BugCheck
指定与内存对齐/必须对齐
指定使用PoolQuota机制
分页池和非分页池是常用的两种内存类型,根据IRQL中断优先级,是否会被页交换中断,具有不同的使用场景.
在win8中引入了NonPagedPoolNx,必须使用它来替代NonpagedPool类型.
SessionPool:在win32k中会经常使用,用于会话空间的分配,对于每个用户会话都是唯一的.
最后一个参数是tag,1-4字符的文本,不存在零字符,用于内核开发人员方便标识调试.
在内核池中,所有单页的数据块的开头都是一个POOL_HEADER结构.这个结构包含了分配器和tag信息.
对windows内核中的堆溢出漏洞进行利用时,首先要进行覆盖的就是POOL_HEADER结构,可以对POOL_HEADER进行重写用于攻击下一个块,或者直接攻击POOL_HEADER.
在这两种情况下,POOL_HEADER结构都会被覆盖.以下是一些字段和作用
1 | struct POOL_HEADER |
2.从win7开始的攻击与缓解措施
Tarjei Mandt及其论文《Windows 7上的内核池攻击》是针对内核池攻击的参考文献.介绍了池的内部结构和攻击,其中的一些攻击以POOL_HEAER为目标.
Quota Process Pointer Overwrite (配额进程指针覆盖攻击)
在这篇文章中提到,因为可以为分配的池内存中对进程进行记录,池分配必须为池算法提供足够的信息.
所以ExAllocatePoolWithQuotaTag将通过POOL_HEADER的ProcessBilled字段指向一个_KPROCESS指针.
攻击者利用堆溢出漏洞去覆盖掉已分配池块POOL_HEADER中的ProcessBilled指针,然后在池被释放时,如果PoolType包含PoolQuota(0x8)标志,那么ProcessBilled字段存储的值将被解引用.
通过覆盖ProcessBilled指针就实现了一个任意指针解引用的原语.在原文中提到了可以通过这个原语进行权限提升.
ps:我没有深入搞清楚是怎样进行利用的.大概是在ExFreePoolWithTag 中由于针对PoolQuota类型池内存的特殊处理,可以有一次任意内存写入的机会.前提是需要伪造一个EPROCESS_QUOTA_BLOCK结构,这里只做了解,不再赘述了.
在win8开始,随着ExpPoolQuotaCookie的引入,这种攻击方式已经被缓解了,该cookie在启动时随机生成,用于保护指针不被攻击者覆盖.它对ProcessBilled字段进行了xor计算.
1 | ProcessBilled = KPROCESS_PTR ^ ExpPoolQuotaCookie ^ CHUNK_ADDR |
并且在释放时,会对ProcessBilled指针进行验证,判断是否为有效的KPROCESS指针.
1 | process_ptr = (struct _KPROCESS *)(chunk_addr ^ ExpPoolQuotaCookie ^ chunk_addr ->process_billed ); |
所以在不知道ExpPoolQuotaCookie的情况下,我们无法伪造一个有效的指针,而实现任意地址的取消引用.
但是,仍然可以通过覆盖POOL_HEADER,且不设置PoolQuota进行攻击.
NonPagedPoolNx
在win8中,引入了新的池内存类型NonPagedPoolNx,它的工作原理与NonPagedPool完全相同,区别是NonPagedPoolNx分配的内存池是不可执行的,缓解了一些内存池中存储shellcode执行的漏洞利用.
但是出于对第三方驱动的兼容性考虑,NonPagedPool仍然可以使用,即使在windows10中,仍有大量第三方驱动使用NonPagedPool分配可执行的池.
随着各种缓解措施的引入,通过溢出攻击POOL_HEADER进行利用非常困难.
目前,通过一个正确的POOL_HEADER攻击下个块的数据实现起来更加简单.但是,需要注意,池中段堆(Segment Heap)引入后,POOL_HEADER的使用发生了改变.本文展示如何再次利用内核的堆溢出漏洞覆盖POOL_HEADER.
2.带有段堆的池分配器
1.段堆内部结构
段堆在win10 19h1开始在内核中开始使用,与用户曾使用的.段堆十分相似,本节主要介绍段堆的主要特性,与用户态的不同之处.
与用户层使用的堆一样,段堆根据分配的大小提供不同的功能,为此,定义了4个后端.
1 | 低碎片堆 |
请求分配的大小与选择后端的映射关系如下图所示
前三个后端,seg,vs,LFH分别关联了对应的上下文:
_HEAP_SEG_CONTEXT,_HEAP_SEG_CONTEXT,_HEAP_SEG_CONTEXT
这些后端的上下文存储在_SEGMENT_HEAP结构中偏移0x100,0x280,0x340的位置
1 | 1: kd> dt nt!_SEGMENT_HEAP |
不同的POOL_TYPE,都有1个_SEGMENT_HEAP,有4种类型,但是实际上存在5个SEGMENT_HEAP结构.第5个段堆的作用未知,PagedPoolSession类型的SEGMENT_HEAP被存储在了当前线程中
1 | NonPaged pools(bit 0 unset) |
在用户态的段堆只有一个段分配器上下文用于128kb-508kb之间的分配,但是在内核的段堆使用2个段分配器上下文,第二个用于508kb-7gb之间的分配.
2.段后端
段后端用于分配128kb-7gb大小的内存块,也在后台用于vs和LFH后端分配内存.
段后端的上下文被存储在_HEAP_SEG_CONTEXT结构当中.
1 | 1: kd> dt nt!_HEAP_SEG_CONTEXT |
段后端,按照大小可变的块分配内存,称为段,每个段由多个可分配的页面组成.
段首由_HEAP_PAGE_SEGMENT开头, 后面是256个HEAP_PAGE_RANGE_DESCRIPTOR结构.
1 | 1: kd> dt nt!_HEAP_PAGE_SEGMENT |
1 | 1: kd> dt nt!_HEAP_PAGE_RANGE_DESCRIPTOR |
为了快速查找空闲页面的范围,在_HEAP_SEG_CONTEXT中维护了红黑树.
每一个_HEAP_PAGE_SEGMENT中都有一个签名,计算方式如下
1 | Signature = Segment ^ SegContext ^ RtlpHpHeapGlobals ^ 0xA2E64EADA2E64EAD ; |
此签名用于从任何已分配的内存块中寻找_HEAP_SEG_CONTEXT和相应的_SEGMENT_HEAP.
3.可变大小后端(VS)
vs可变大小后端,用于分配512b-128kb大小的块,用于对空闲块的重用.
这是vs后端的上下文结构:_HEAP_VS_CONTEXT
1 | 1: kd> dt nt!_HEAP_VS_CONTEXT |
空闲块存储在偏移0x8处的FreeChunkTree红黑中,当请求分配时,红黑树被用来查找请确大小的空闲块或第一个大于请求大小的空闲块.
空闲块通过一个_HEAP_VS_CHUNK_FREE_HEADER的结构体作为header.
1 | 1: kd> dt nt!_HEAP_VS_CHUNK_FREE_HEADER |
当找到空闲块时,会调用函数RtlpHpVsChunkSplit对空闲块进行分配,或者进行分割为大小合适的块.
分配的块通过结构体_HEAP_VS_CHUNK_HEADER存储.
1 | 1: kd> dt nt!_HEAP_VS_CHUNK_HEADER |
1 | 1: kd> dt nt!_HEAP_VS_CHUNK_HEADER_SIZE |
在header结构体中,所有的字段都会与RtlHpHeapGlobals和块的地址进行异或
1 | Chunk ->Sizes = Chunk ->Sizes ^ Chunk ^ RtlpHpHeapGlobals ; |
4.低碎片堆后端(LFH)
低碎片堆后端LFH,是用于分配1b-16368b的小块的后端.
LFH后端的上下文结构如下
1 | 1: kd> dt nt!_HEAP_LFH_CONTEXT |
LFH后端中,使用了大小不同的bucke以避免碎片化
每一个bucket由段分配器分配的字段组成,段分配器在_HEAP_LFH_CONTEXT结构体的_Callbacks字段进行使用,
对应的结构体为_HEAP_SUBALLOCATOR_CALLBACKS.
1 | 1: kd> dt _HEAP_SUBALLOCATOR_CALLBACKS |
LFH的子段的结构体为:_HEAP_LFH_SUBSEGMENT
1 | 1: kd> dt _HEAP_LFH_SUBSEGMENT |
每个子段被分割成大小不同的LFH块,对应的bucket也是不同的,为了标识字段使用的是哪个bucket,在每个字段的header中通过BlockBitmap的位图中进行了记录.
当请求分配一个小块的内存时,LFH分配器首先查找_HEAP_LFH_SUBSEGMENT结构中的FreeHint字段,找到子段中最后释放的块的偏移,然后扫描BlockBitmap,按32个区块为一组,寻找空闲区块.
5.动态快表(Dynamic Lookaside)
大小为0x200-0xf80字节的空闲块可以暂时存储到快表中,以便快速分配,当这些块存储到了快表时,就不会通过它们对应的后端进行释放了.
快表的结构体为_RTL_DYNAMIC_LOOKASIDE,存储_SEGMENT_HEAP结构体的UserContext中
1 | 1: kd> dt _RTL_DYNAMIC_LOOKASIDE |
每一个释放的块和大小存储在了结构_RTL_LOOKASIDE中,大小的对应关系遵循与LFH bucket相同的模式.
1 | 1: kd> dt _RTL_LOOKASIDE |

为什么叫动态快表呢,因为每次请求分配时,对应的快表属性都会进行更新.
Balance Set Mangager每扫描三次,动态快表都会重新平衡,每个快表的大小不能超过MaximumDepth,不能小于4.
并且通过命中率对Depth进行动态调整.
6. POOL_HEADER
在win10 19h1前,内核分配的池都以POOL_HEADER开头,并且所有的字段都被使用,然而在更新之后,POOL_HEADER大部分字段是无用的,但是已分配的小块内存仍在使用.
1 | struct POOL_HEADER |
内核堆分配器设置的字段如下
1 | PoolHeader ->PoolTag = PoolTag; |
在win19h1后,POOL_HEADER中字段的用途
1 | PreviousSize; 未使用,始终为0 |
7.缓存对齐
调用了ExAllocatePoolWithTag时,如果PoolType设置了CacheAligned,那么返回的内存将是与缓存行大小对齐的,这个值取决于cpu,通常为0x40.
首先分配器,会增加ExpCacheLineSize的大小
1 | if ( PoolType & 4 ) |
如果新的分配大小,不能容纳在单个页面中,那么CacheAligned将会被忽略,
这种情况下,分配的块必须遵循以下三个条件:
1.最终分配的地址必须与ExpCacheLineSize对齐
2.数据块的开头必须有一个POOL_HEADER
3.分配的地址-sizeof(POOL_HEADER)的地址处必须有一个POOL_HEADER
如果分配的地址没有正确的对齐,那么块就可能会有2个Headers.
第一个POOL_HEADER正常位与数据块的开头,第二个POOL_HEADER将按照ExpCacheLineSize-Sizeof(POOL_HEADER)对齐,是最终分配地址按照ExpCacheLineSize对齐.第一个POOL_HEADER中的CacheAligned将被移除,第二个POOL_HEADER将进行如下填充.
1 | PreviousSize:用来保存两个header之间的偏移 |
如果,对齐填充中有足够的空间,还可以在POOL_HEADER之后在存储一个指针,称之为AlignedPoolHeader.它指向第二个POOL_HEADER
8.概述
自从win19h1引入段堆之后,POOL_HEADER中的一些信息就已经不需要了,但是其他字段如PoolType,PoolTag和使用PoolQuota机制的情况下是仍然会使用的.
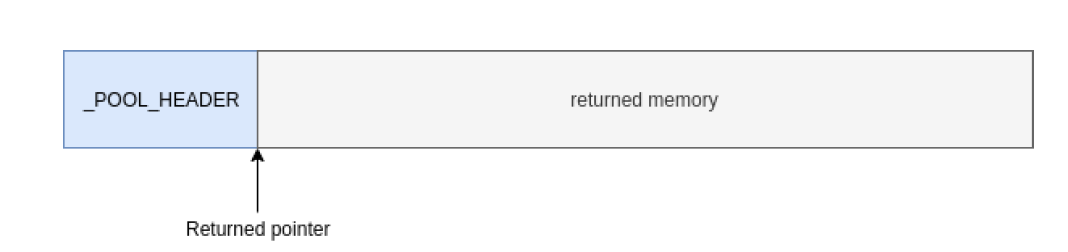
这就是为什么分配小于0xFE0块都会至少还有一个POOL_HEADER头,下图标识LFH后端分配的一个数据块,前面只有一个POOL_HEADER头.分配的地址是POOL_HEADER后面的地址.
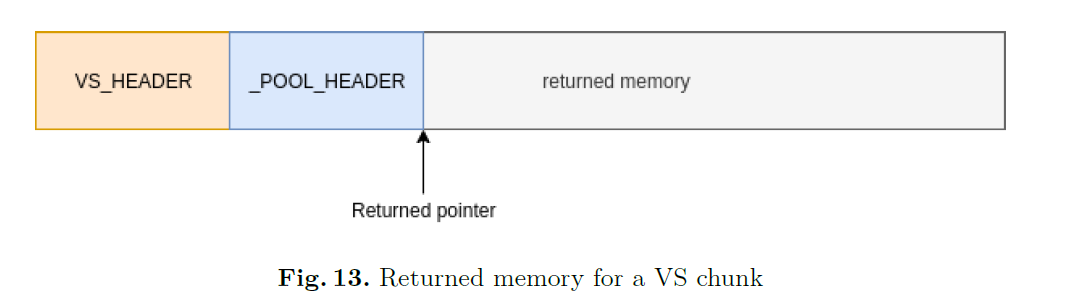
不同的后端所申请的内存块的header结构是不同的,如果使用VS后端分配了大小为0x280的内存,那么这快内存将以VS_HEADER作为头部后面则是POOL_HEADER
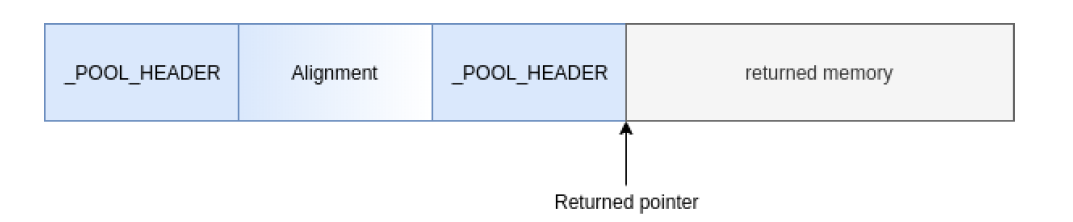
如果分配要涉及到CacheAligned的对齐,那么分配的内存可能会包含2个POOL_HEADER,第二个POOL_HEADER的CacheAligned位将会被设置,用于检索第一个块和实际分配的地址.下图是一个LFH后端申请的数据块,并且要求与设置的缓存大小对齐,所以前面有2个POOL_HEADER
从利用的角度上来看,可以得出2个结论,再19h1以后,POOL_HAEDER的大部分字段未被使用,所以利用时很多字段可以直接覆盖.第二是因为POOL_HADER多了很多新的用法,可以寻找新的利用技术.
3.攻击POOL_HADER
如果堆溢出漏洞可以很好地控制写入的数据和大小,那么最简单的解决方案就是通过覆盖重写POOL_HADER,然后攻击下一个块的数据,唯一要做的事情就是覆盖时确认没有设置PoolQutota位,避免在释放时对ProcessBilled字段进行检查.
不过,在本节中,将针对POOL_HEADER提供一些只需要几个字节的堆溢出就可完成利用的方法.
下图是一个段堆分配器的决策流程
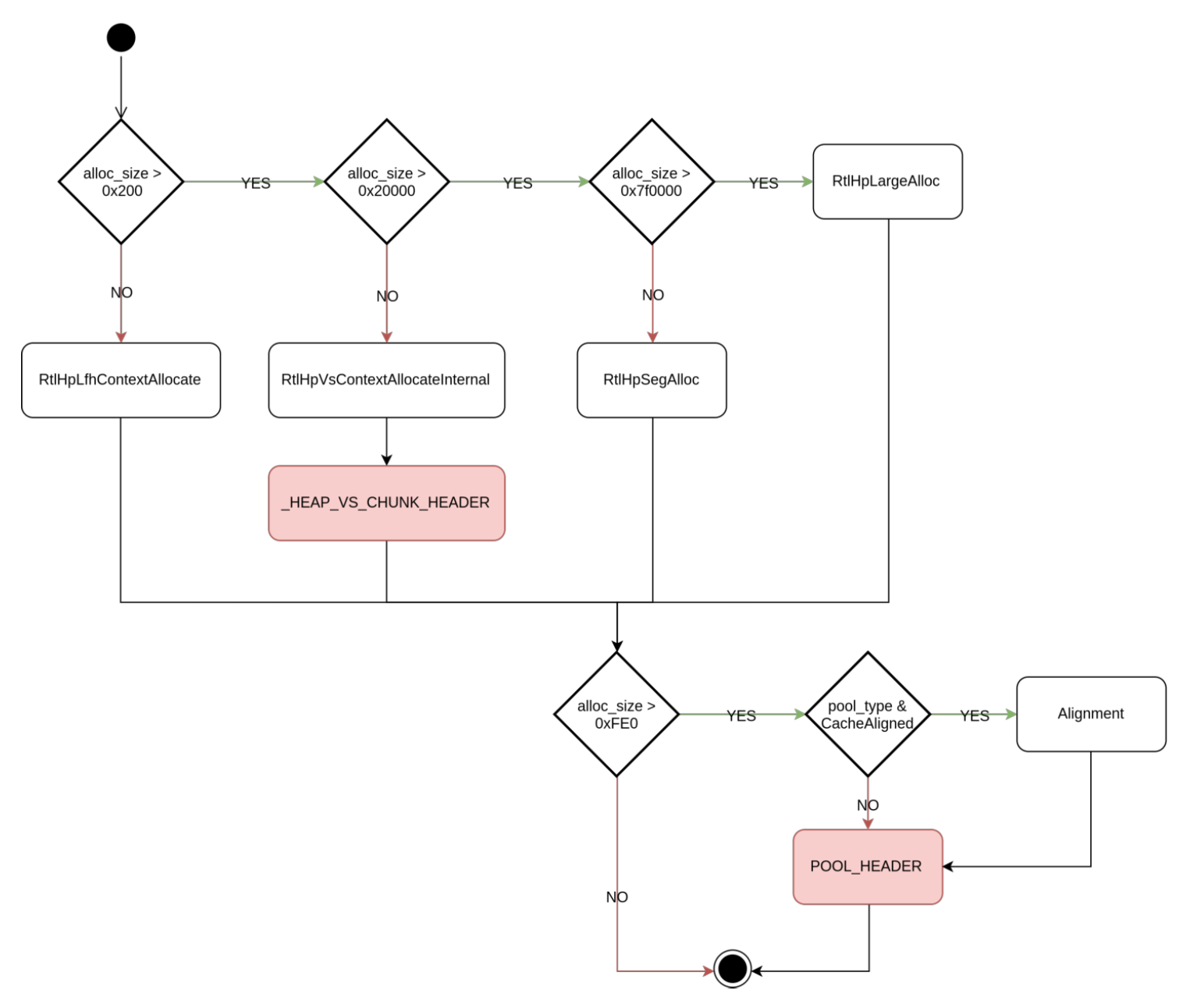
1.篡改BlockSize,从BlockSize堆溢出到更大的堆溢出
在前面提到的,将块存储到动态快表时,BlockSize表示块的大小.
攻击可以通过堆溢出漏洞间BlockSize字段的值使其变的更大,将这个值改为大于0x200的值,如果被破坏的数据块已被释放,那么这个被释放的数据块的大小与BlockSize记录的大小是不同的,这个错误的大小的块被存储在快表中,当再次申请内存,申请到这个块时,通过这个较小的内存去存储更大的数据,就会再次触发堆溢出,而这个堆溢出的范围将是更大的.
通过使用堆喷和一些对象,攻击者可以将3字节的堆溢出覆盖BlockSize,通过上述方法转变为高达0xFD0字节的堆溢出,取决于攻击的块的大小.攻击者还可以选择溢出的对象,并对溢出条件进行更多控制.
2.篡改PoolType
在大多数情况下,存储在PoolType中的数据只是作为分配时提供并存储在PoolType中,不会用于释放机制.
所以,更改存储在PoolType中的内存类型实际上不会改变分配所使用的内存类型,更不可能将NonPagedPoolNx类型内存更改为NonPagedPool.
但是PoolQuota和CacheAligned位的情况并不是这样,如果设置了PoolQuota位,那么在释放的时候,将会对ProcessBilled指针做处理,取消引用,但是针对于ProcesssBilled的攻击已经被缓解,会进行验证.
所以,只剩下了CacheAligned位.
块排列混淆
如前面所讲,如果请求分配的PoolType中的CacheAligned被设置,分块的布局就会不同.
分配器在释放这种类型的内存时,会尝试查找原始的块地址,用来在正确的地方释放,它将在对齐了的POOL_HEADER中找到PreviousSize字段,然后分配器会通过计算,获得原始块的地址.
1 | if ( AlignedHeader ->PoolType & 4 ) |
在内核引入段堆之前,该操作之后有几项检查
1.分配器检查原始块是否在PoolType中设置了MustSucceed位.
2.使用ExpCacheLineSize重新计算了2个头之间的偏移量,验证两个头之间的偏移量
3.分配器检查已对齐标头的BlockSize是否等于原始标头的BlockSize+已对齐标头的PreviousSize
4.分配器检查OriginalHeader中保存的指针加上POOL_HEADER的大小是否等于对齐头的地址与ExpPoolQuotaCookie xor的值.
在win10 19h1后,池分配器使用了段堆,这些检查都不存在了,但是xor的指针仍然存储在原始头之后,但是在释放的时候不会进行检查,作者认为有一些检查被错误的删除,某些检查可能会在未来的版本中重新启用,但是在win10 20h1的预编译的版本中并未显示此类补丁.
目前,由于缺乏检查,攻击者可以利用 PoolType 作为攻击向量.攻击者可能会利用堆溢出设置下一个数据块的 PoolType 的CacheAligned 位,并完全控制 PreviousSize 字段.当分块被释放时,释放机制会使用受控的 PreviousSize 来查找原始分块,并将其释放.由于 PreviousSize 字段存储在一个字节上,攻击者可以释放任何与 0x10 对齐的地址,最高可达原始块地址之前的 0xFF * 0x10 =0xFF0.
本文的最后一部分介绍了一种通用漏洞利用的技术,他介绍了池溢出或UAF情况下值得被控制的通用对象,以及使用受控数据重用自由分配的多种对象和技术.
4.通用漏洞利用开发
1.必要条件
本节介绍的漏洞利用实现了windows权限提升技术,假设攻击者处于低完整性级别.
最终目的是开发出最通用的漏洞利用程序,可用于不同类型的内存(PagedPool和NonPagedPoolNx),不同大小的块以及任意堆溢出漏洞,这些漏洞需要满足以下条件.
1.当以BlockSize为攻击目标时,漏洞需要提供一个受控值重写下一个分块的POOL_HEADER的第3个字节.
2.当以PoolType攻击目标时,漏洞需要提供受控值,重写下一个分块的POOL_HEADER的第1和第4个字节.
在所有情况下,都需要控制漏洞对象的分配和释放,以便提高堆喷的成功率.
2.利用策略
所选择的利用策略是利用攻击下一个数据块的POOL_HEADER的PoolType和PreviousSize的能力.触发漏洞的块被称为Vulnerable chunk,被覆盖的块称为Overwritten chunk.
如前面所讲,通过控制下一个分块的POOL_HEADER的PoolType和PreviousSize字段,攻击者可以改变被覆盖块的释放位置.利用这种方式有多种途径.
如下图,当攻击者将PreviousSize字段设置为计算后恰好等于Vulnerable Chunk的位置,在释放Overwritten chunk时,Vulnerable Chunk将会被释放.并且处于UAF的状态.

不过我们选择了另外一种技术,如下图,这种方法可以在Vulnerable Chunk中间触发Overwritten Chunk的释放.
可以在Vulnerable Chunk中伪造一个POOL_HEADER,并且使用PoolType攻击来重定向Vulnerable Chunk的空闲空间,这将在合法的块中创建了一个虚假的块,从而达到一个很好的溢出效果.通过这种方式构造出的大块被称为ghost chunk.

ghost chunk至少覆盖2个块,即Vulnerable chunk和Overwritten chunk.
这种方法看起来比UAF更好利用,因为它可以让攻击者更好的控制任意对象的内容.
然后,攻击者就可以用任意数据控制的对象重新分配有漏洞的数据块,这样攻击者就可以控制部分ghost chunk中分配的对象.
必须找到一个有趣的对象,才能将其放入幽灵块,为了尽可能实现最通用的利用,该对象应该满足以下要求:
1.在完全或者部分控制的情况下,可以实现任意地址读写原语
2.拥有控制这个对象分配和释放的能力
3.具有最小0x210的可变大小,以便从相应的快表分配到ghost chunk中,但应尽可能小(避免分配时浪费太多堆空间)
为了vulnerable chunk可以放在PagePool和NonPagedPoolNx中,因此需要2个这样的类对象,一个在PagedPool中分配,一个在NonPagedPoolNx中分配.
但是这种对象不是常见的,作者也没有找到这种完美的对象,所以开发了一种利用策略.使用一个只能提供任意地址读原语的对象.攻击者仍然能控制ghost chunk的POOL_HEADER,这意味着之前提到的Quota Pointer Process Overwrite攻击可以被用于获取任意减量原语,ExpPoolQuotaCookie和ghost chunk的地址可以使用任意读取原语恢复.
开发的漏洞利用使用的就是这个技术,通过利用堆处理和有趣的对象溢出,实现4字节的受控溢出变成权限提升,有低完整性级别提升到system.
3.目标对象
在分页池创建管道后,用户可以向管道添加属性,属性是键值对,存储在一个链表中.PipeAttribute对象在分页池中分配,内核中的结构如下
1 | struct PipeAttribute { |
PipeAttrubute对象的分配和数据的大小完全由攻击者控制,AttributeName和AttributeValue 是指向数据字段不同偏移量的指针.
可以使用NtFsControlFile系统调用和0x11003C控制代码在管道上创建管道属性.
然后可以使用 0x110038 控制代码读取属性值.AttributeValue指针和 AttributeValueSize 将用于读取属性值并返回给用户.属性值可以更改,但这将会触发先前 PipeAttribute 的释放和新属性的分配.
1 | HANDLE read_pipe; |
这 意 味 着 , 如 果 攻 击 者 可 以 控 制 PipeAttribute 的AttributeValue 和 AttributeValueSize 字段,就可以读取内核中的任意数据,但不能任意写入.该对象也非常适合在内核中放置任意数据.这意味着它可以用来重新分配易受攻击的分块并控制 ghost 分块的内容.
NonPagedPoolNx
通过WriteFile写入管道是一种已知的喷射NonPagedPoolNx技术,在向管道中写入时,NpAddDataQueueEntry函数会创建下图所示的结构体.
1 | struct PipeQueueEntry |
PipeQueueEntry2 的数据和大小由用户控制,因为数据直接存储在结构后面.
在使用函数 NpReadDataQueue 中的条目时,内核将遍历条目列表,并使用每个条目检索数据.PipeQueueEntry的数据和大小
如果 isDataInKernel 字段等于 1,则数据不会直接存储在结构体后面,而是将指针存储在由 linkedIRP 指向的 IRP 中.如果攻击者可以完全控制该结构,他可能会将 isDataInKernel 设置为 1,并将linkedIRP 指向用户域.然后,用户区中 linkedIRP 的 SystemBuffer字段(偏移量 0x18)就会被用来从条目中读取数据.这提供了一个任意读取的基元.该对象也非常适合在内核中放置任意数据.这意味着它可以用来重新分配易受攻击的分块并控制幽灵分的
内容.
1 | if ( PipeQueueEntry->isDataAllocated== 1 ) |
4.堆喷射
本节将介绍堆喷射技术,以获得所需的内存布局.
为了获得之前讲到的ghost chunk所需的内存布局,必须进行一些对喷射.对喷射取决于Vulnerable Chunk的大小,不同的大小会通过不同的分配后端,结构也可能不同.
为了简化堆喷的过程,确保相应的快表是空的,分配超过256个大小合适的大块可以确保这一点.
如果易受攻击的数据块小于 0x200,那么它将位于 LFH 后端.然后,用完全相同的块进行喷射,以相应的bucket粒度为模,确保它们全部都是从同一个bucket中分配.如前面所讲,当请求分配时,LFH后端将通过以下方式扫描BlockBItmap:以32个区块为一组,随机选择一个空闲区块.
在分配vulnerable chunk的前后个分配超过32个合适大小的区块有助于克服随机化.
如果vulnerable chunk的块大小大于0x200,但是小于0x1000,那么将由可变大小后端进行分配.然后通过与vulnerable chunk大小相同的数据块进行喷射的话,大块可能会被分割,从而导致喷射失败.
首先,分配上千个选中大小的块,以确保首先清空FreeChunkTree中所有大于所选大小的块.
然后,分配器将分配0x10000字节的新VS字段,并将其放入FreeChunkTree.
然后再分配几千个分块,这些分块最终会进入新的大空闲分块,因此是连续的,然后释放最后分配的块的3分之1,用于填充FreeChunkTree,只是放3分之1将确保不会有数据块合并,最后重新分配已释放的数据块,以最大限度增加喷射机会.
由于所有的利用技术都需要重新分配和释放vulnerable chunk和ghost chunk,因此启用相用的动态快表以简化空闲块的恢复过程,确实很有趣,要做到这点,一个简单的方法是分配数千个相应大小的块,等待2秒,再分配数据千个块,等待一秒,这样我们就能确保平衡管理器重新平衡了相应的快表,分配上千个块可以确保该快表处于使用率最高的快表中,从而被启用,并且确保它有足够的空间.
5.利用
为了演示下面的漏洞利用.我们创建了一个假漏洞.
我们开发了一个windows驱动,公开了一个IOCTL,允许开发人员调用,可以做这些操作:
1.在PagedPool中分配大小受控的分块
2.触发该块中的受控memcpy,允许完全受控的池溢出
3.释放已分配的数据块
当然这只是为了做演示,提供了一些控制功能,实际需要让漏洞发挥作用.
这些设置允许攻击者:
1.控制vulnerable chunk的大小,这不是必须的,但是最好这样做,因为控制了大小,漏洞利用就更容易了.
2.控制vulnerable chunk的分配和删除
3.使用可控的值覆盖掉下个数据块POOL_HEADER前4字节.
此外vulnerable chunk是在PagedPool进行分配的,这一点很重要,因为池的类型会改变漏洞利用中使用的对象,进而堆漏洞利用本身产生重大影响.此外,针对NonPagedPoolNx的利用非常相似,使用PipeQueueEntry就可以替代PipeAttribute,实现喷射并得到任意地址读写原语.
在这个例子中,所选的漏洞块大小为0x180,关于易受攻击的数据块大小及其漏洞利用的影响,将在后面讨论.
创建ghost chunk
第一步是对堆进行处理,以便在vulnerable chunk后放置一个受控对象.
覆盖块中的对象可以是任何东西,唯一的要求是控制它何时被释放,为了简化漏洞利用,最好是选择一个可以喷射的对象.
现在可以触发漏洞了,被覆盖的POOL_HEADER将被以下值替换:
PreviousSize:0x15,此大小将*10.0x180-0x150=0x30.即vulnerable chunk中伪造POOL_HEADER的偏移量.
PoolIndex:0或者为任意值,未使用
BlockSize:0或者为任意值,未使用
PoolType:PoolType|4,设置CacheAligned位
下图是一个触发溢出时的内存结构

伪造的POOL_HEADER必须放在vulnerable chunk的已知偏移位置,具体做法是释放vulnerable chunk中的对象,然后使用PipeAttribute重新分配该块.
在演示中,伪造的POOL_HEADER在vulnerable chunk数据块中的偏移量位0x30,伪造的POOL_HEADER形式如下:
PreviousSize:上一个大小,0或者任何值,不使用
PoolIndex:0或者为任意值,未使用
BlockSize:0x21,该值将*0x10,即为释放的块大小
PoolType:PoolType,不设置CacheAligned和PoolQuota位
BlockSize的值不是随机的,而是实际释放的块的大小,由于我们的目标是在分配后重复使用,因此需要选择一个易于重用的大小,由于所有小于0x200的块都在LFH中,因此必须避免这种大小,非LFH的最小大小是0x200的分配,也就是大小为0x210的块,0x210使用VS分配,可以使用动态快表.
通过喷射和释放0x210大小的数据块,可以启用大小为0x210字节的动态快表.
现在可以释放被覆盖的块,由于我们设置了CacheAligned,这将触发缓存对齐,它不会释放Overwritten chunk数据块的地址,而是释放OverwrittenChunkAddress-(0x15*0x10)处,也就是vulnerablechunkAddr+0x30处用于释放的POOL_HEADER也是我们进行伪造的,内核没有释放vulnerable chunk,而是释放了一个大小为0x210的数据块FreeGhostChunk,并将其放置在动态快表的顶部.

遗憾的是,虚假的POOL_HEADER的PoolType并不影响释放的分块是放在PagedPool还是NonPagedPoolNx中,动态快表是由分配的段来选择的,而分配的段来自于分块的地址,这意味着vulnerable data chunk在PagedPool,那么Ghost Chunk也会放放置在PagedPool的动态快表中.
被覆盖的数据块现在处于丢失状态,内核会认为它已经被释放,并且该数据块上的所有引用都已删除,不会再被使用.
泄露ghost chunk
现在ghost chunk可以通过PipeAttrubute对象重新分配了,PipeAttribute结构会覆盖放在vulnerable data chunk中的属性值,通过读取该管道数据的值,就可以读取数据,而ghost chunk的PipeAttribute内容则会泄露,现在我们已经知道了ghost chunk的地址,也就是vulnerable data chunk的地址,如下图所示.
任意地址读原语
vulnerable data chunk可以在另一次释放后,用其他的PipeAttribute重新分配,这一次分配后,PipeAttribute的数据将覆盖ghost chunk的PipeAttribute.因此,可以完全控制ghost chunk的PipeAttribute.一个新的PipeAttribute被注入到位于用户层的列表中.如下图所示.
现在,通过请求读取ghost的PipeAttribute上的属性,内核将使用用户层的PipeAttribute,因此可以实现完全控制.如前面所述,通过控制AttributeValue指针和AttributeValueSize,可以实现一个任意地址读取的原语.

使用泄露的第一个指针和任意读原语,可以检索npfs代码段的指针,通过读取导入表,可以读取ntoskrnl代码段的指针.这提供了内核的基址,攻击者可以读取ExpPoolQuotaCookie的值,并获取漏洞利用进程中的EPROCESS结构和其TOKEN地址.
任意递减原语
首先,在内核中使用PipeQueueEntry制作一个假的EPROCESS机构,并使用任意地址读取检索它的地址.
然后,攻击者可以再次释放并重新分配vulnerable chunk,以更改ghost chunk和它的POOL_HEADER中的内容.
ghost chunk中的POOL_HEADER进行如下设置:
PreviousSize:0或者任何值,不使用
PoolIndex:0或者为任意值,未使用
BlockSize:0x21,该值将*0x10,即为释放的块大小
PoolType:8,设置PoolQuota位
PoolQuota:ExpPoolQuotaCookie xor FakeEprocessAddress xor GhostChunkAddress
释放ghost chunk后,内核将尝试解引用EPROCESS的Quota count,它使用我们伪造的EPROCESS结构来查找指向要取消引用的值的指针.
这将提供任意递减原语,递减值是PoolHeader中的BlockSize,因此它在0x0-0xff0,以0x10对齐.
从任意递减到System权限提升
在2022年,Cesar Cerrudo描述了一种通过设置Token结构的Privileges.Enabled字段提升权限的技术.Privileges.Enabled字段用 于 保存该进程已启用的权限.默认情 况 下 , 低完整性级别token的 Privileges.Enabled 设 置 为0x0000000000800000,它只提供 SeChangeNotifyPrivilege 权限.如果
在该位字段上减一,它就会变成 0x000000000007ffff,从而启用更多权限.
通过设置该位字段的第 20 位,可以启用 SeDebugPrivilege.SeDebugPrivilege 允许一个进程调试系统中的任何进程,因此可以在特权进程中注入任何代码.
文中介绍了Quota Process Pointer Overwrite技术,可以使用任意递减原语来设置进程的SeDebug权限.
下图介绍了这种技术.
不过从win10 1607版本开始,内核现在也会检查token的Privileges.Present 字段的值.token的 Privileges.Present 字段是通过使用 AdjustTokenPrivileges API(调整token特权 API)为该token启用权限列表的.因此token的实际权限就是Privileges.Present和Privileges.Enable字段决定.
默认情况下,低完整性级别的token中Privileges.Present 设置为0x602880000,由于0x602880000 & (1<<20) ==0,在Privileges.Enabled 中 设 置 SeDebugPrivilege 不 足 以 获 得SeDebugPrivilege.一 种 方 法 是 递 减 Privileges.Present 比 特 字 段 , 以 便 在Privileges.Present 比特字段中获取SeDebugPrivilege.然后,攻击者可以使用 AdjustTokenPrivileges API 来启用 SeDebugPrivilege.然
而,SepAdjustPrivileges 函数会进行额外检查,根据 TOKEN 的完整性,进程无法启用任何权限,即使想要的权限在 Privileges.Present位域中.对于高完整性级别,进程可以启用 Privileges.Present 字段中 的 任 何 权 限 . 对 于 中 完 整 性 级 别 , 进 程 只 能 启 用Privileges.Present 和 0x1120160684 位字段中的特权.对于低完整性级别,进程只能启用 Privileges.Present 和位字段 0x202800000 中的权限.
这意味着,这种通过一次任意递减获得 SYSTEM 的技术已经失效.
不过,也完全可以通过两次任意递减来实现,首先递减Privileges.Enabled,然后递Privileges.Present.
可以重新分配幽灵块,并第二次覆盖其 POOL_HEADER,以获得第二次任意递减.一 旦 获 得 SeDebugPrivilege , 漏 洞 利 用 者 就 可 以 打 开 任 何SYSTEM 进程,并在其中注入 shellcode,以 SYSTEM 身份弹出 shell.
关于漏洞对象的大小
根据易受攻击对象的大小,漏洞利用可能会有不同的要求.上述漏洞利用方法只适用于最小大小为 0x130 的易受攻击数据块.这是因为幽灵分块的大小必须至少为 0x210.如果易受攻击的块大小小于 0x130,ghost 块的分配就会覆盖被覆盖块后面的块,释放时就会引发崩溃.这个问题是可以解决的,但留给读者一个练习.LFH 中的易受攻击对象(0x200 以下的数据块)与 VS 段中的易
受攻击对象(大于0x200)有一些不同之处.主要原因是 VS 块前面有一个额外的头.这意味着要控制VS 段中下一个分块的 POOL_HEADER,堆溢出至少需要 0x14 字节.这也意味着,当被覆盖的分块被释放时,它的_HEAP_VS_CHUNK_HEADER 必须得到修复.此外,必须注意不要释放紧随被覆盖的数据块之后的 2 个数据块,因为 VS 的释放机制可能会读
取被覆盖数据块的 VS 标头,试图合并 3 个空闲数据块.最后,正如前面所讲,LFH 和 VS 中的堆批量处理有很大不同.
5.结论
本文介绍了 Windows 10 19H1 更新后的池内部状态.段堆(Segment Heap)已被引入内核, 它不需要分块元数据即可正常工作.不过,以前位于每个分块顶部的 POOL_HEADER 仍然存在,只是使用方式不同.我们演示了在 Windows 内核中使用堆溢出进行攻击的一些方法,具体方法是攻击池的内部结构.
所演示的漏洞利用程序可适用于任何提供最小堆溢出的漏洞,并允许将本地权限从 “低完整性 “级别升级到 “系统 “级别.