之前分析afl-fuzz源码的时候,看到了llvm pass相关代码,就想着学习下这块的混淆和反混淆技术,跟着写一些常见的混淆.(^_^)
LLVM 代码混淆技术
LLVM是具有很多模块的编译框架,区别于GCC,是一个可拓展的,模块化的编译器.
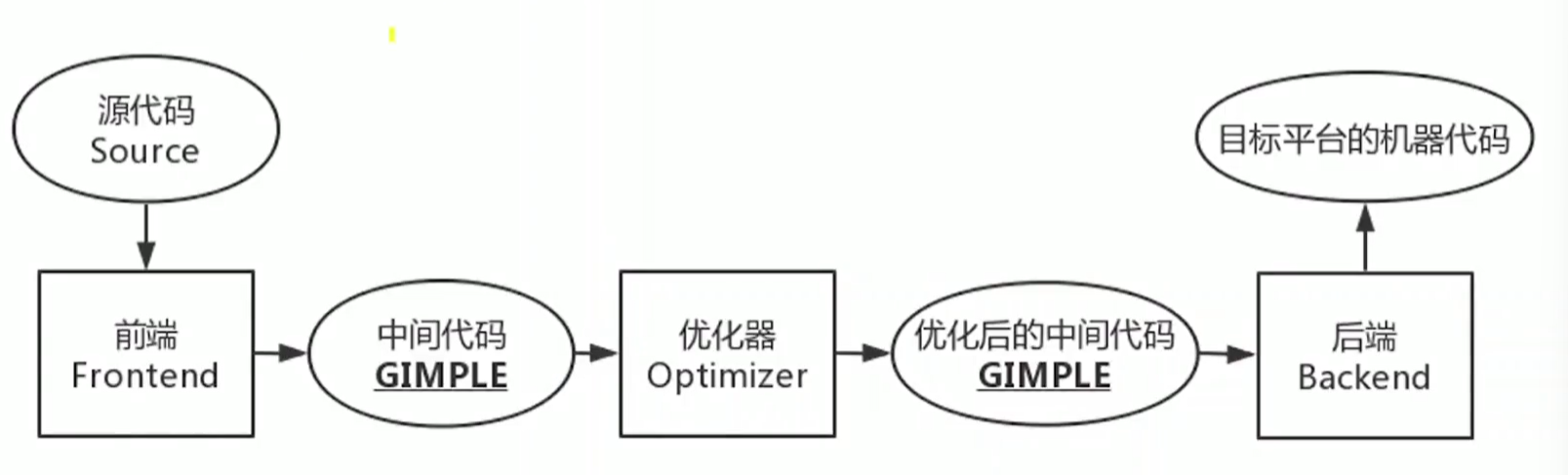
1.GCC编译流程
GCC模块分为前端,优化器,后端.
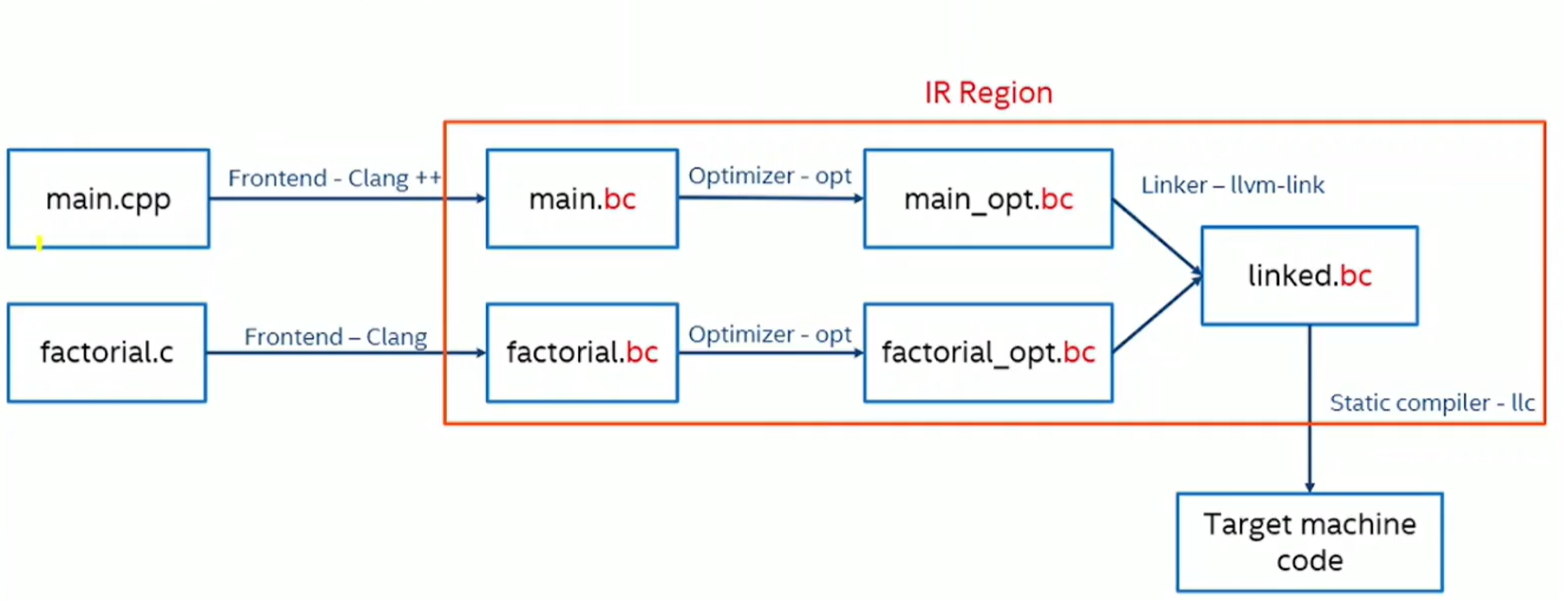
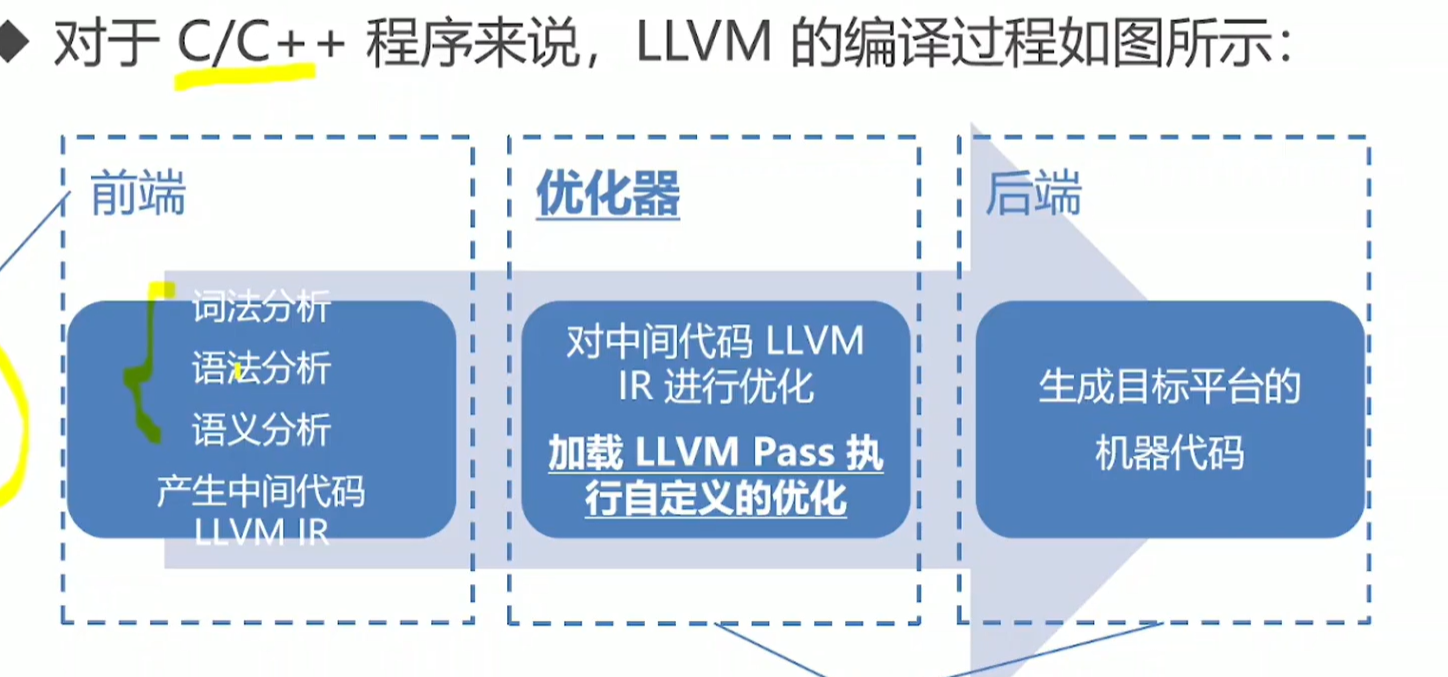
2.LLVM编译流程
LLVM与之相同,LLVM的中间代码叫做LLVM IR.
代码的混淆通过LLVM pass实现.LLVM pass框架是LLVM提供给用户用来干预优化过程的框架.
编译后的LLVMPass通过优化器opt进行加载,对LLVM IR中间代码进行分析和修改,生成新的中间代码.
LLVM的三种编译模式,最常用的应该是第二种,编译速度快而且方便管理.
1.与整个LLVM一起编译,Pass代码存放于llvm/lib/Transforms
2.通过CMake对Pass进行单独编译.
3.使用命令行对pass进行单独编译.
3.LLVM Pass
Pass类型
ModulePass:基于模块的Pass
FunctionPass:基于函数的Pass
CallGraphPass:基于调用图的Pass
LoopPass:基于循环的Pass
….
FuncitonPass
以函数为单位进行处理
Function的子类必须实现runOnFunciton(Funciton &F)
FunctionPass运行时,会对程序的每个函数执行一次runOnFunction()
1.创建一个类,继承FunctionPass父类.
2.子类实现runOnFunction(Function &F)
3.向LLVM注册Pass类
4.LLVM IR
LLVM IR类似与汇编,是一种低级编程语言.任何高级编程语言都可以用LLVM IR表示,所以基于LLVM IR可以很方便的进行代码优化.
LLVM IR文件中有两种表示方式.
一种是可读的形式,后缀为.ll,一种为二进制的形式,后缀为.bc,二者是可以相互转换的.
通过llvm-dis将.bc转换为.ll
通过llvm-as将.ll转换为.bc
LLVM IR的结构
基于LLVM的混淆,通常以函数和比函数更小的基本单位进行混淆的.
以函数为单位的混淆:控制流平坦化
以为单位的混淆:虚假控制流
以指令为基本单位的混淆:指令替代
Module(模块)
LLVM IR中,模块是最顶层的单位,一个个模块代表一个编译单元,通常对应一个源代码文件,包含例如函数定义,函数声明,全局变量等全局符号.
Funciton(函数)
函数是LLVM IR中非常重要的单位,函数由函数头和函数体组成.函数头包括函数名,参数列表,返回数据类型.函数体由一系列指令构成的Basic Block(基本块)组成.
Basic Block(基本块)
基本块是LLVM IR的基本执行单元,有若干个指令和标签组成,正常情况下基本块的最后一条指令为跳转指令或返回指令,也叫终结指令.
还存在一些PHI指令.
Instruction(指令)
LLVM中的最小执行大怒预案,表示一个操作或者一个控制流操作,由操作码和操作数组成.
LLVM IR的指令
其实与x86汇编类似,重点是一些特殊的其他指令.
终结指令
ret
返回指令
1 | ret <type> <value> |
br
跳转指令
1 | //条件跳转jz,je,jnz,jne..... |
icmp
比较指令
1 | <result> = icmp <cond> <ty> <op1>,<op2> ; 比较op1,op2是否满足cond |
switch
分支指令
1 | swtich <intty>//类型 <value>//值,lable <defaultdest>//默认分支 [<intty> <val>,label <dest> ...] |
二元运算相关
add
加法
1 | <result> = add <ty> <op1>,<op2> |
sub
减法
1 | <result> = sub <ty> <op1>,<op2> |
mul
乘法
1 | <result> = mul <ty> <op1>,<op2> |
udiv/sdiv
udiv无符号除
sdiv有符号除
1 | <result> = udiv <ty> <op1>,<op2> |
urem/srem
无符号取余/有符号取余
1 | <result> = urem <ty> <op1>,<op2> |
按位二元运算相关
shl
左移
1 | <result> = shl <ty> <op1>,<op2> |
lshr/ashr
逻辑右移/算数右移
1 | <result> = lshr <ty> <op1>,<op2> |
and/or/xor
按位与/按位或/按位异或
1 | <result> = and <ty> <op1>,<op2> |
内存访问和寻址
静态单赋值
IR的一种属性.LLVM IR是基于静态单赋值原则设计的
SSA:在程序中一个变量仅能有一条赋值语句
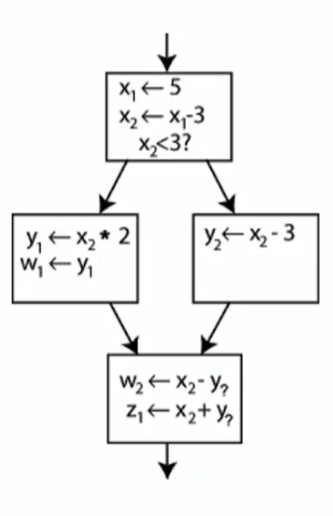
不满足SSA
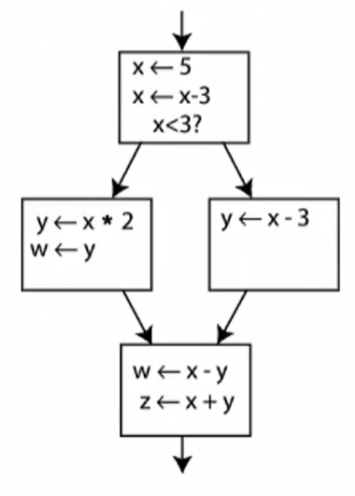
满足SSA
alloca
栈中分配空间
1 | <result>=alloca <type> [,<ty> <NumElements>] [,align <alignment>] ;分配sizeof(type)*NumElements字节的内存,分配的地址与alignment对齐 |
store
内存存储指令,向指针指向的内存中存储数据
1 | store <ty> <value>,<ty>* <pointer> |
load
内存读取
1 | <result> = load<ty>,<ty>* <pointer> |
类型转换相关
trunc .. to
大类型向小类型转换
1 | <result>= trunc <ty> <value> to <ty2> |
zext .. to
小类型转大类型(高位补0)
1 | <result>= zext <ty> <value> to <ty2> |
sext .. to
复制符号位的转换
1 | <result>= sext <ty> <value> to <ty2> |
其他指令
phi指令
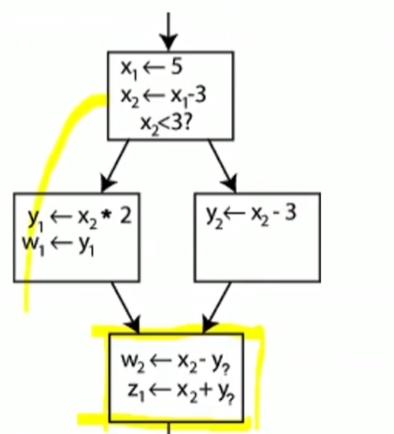
以上流程,如果是从左侧基本快执行至最后,y的值为y1,从右侧则为y2.
为了解决SSA引起的变量不明确问题,引入了Φ函数解决这个问题.也就是phi指令.
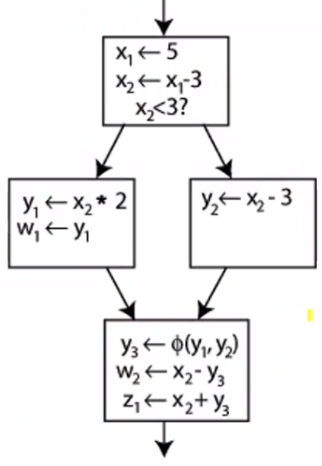
phi指令的计算结果,由指令所在的基本块的前驱块确定的.
1 | <result>=phi <ty> [<val0>,<label0>],...;如果前驱块为label0,则result=val0 |
select
三元运算符
1 | <result> = select il <cond>,<ty> <val1>,<ty> <val2> |
call
调用函数指令
1 | <result> call <ty>|<funty> <fnptrval>(<function args>) |
5.LLVM PASS API
基本类
Value
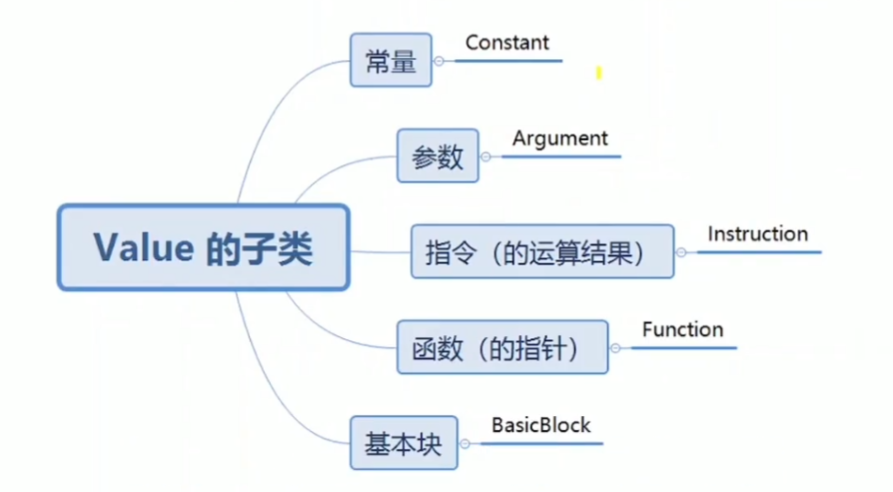
核心类
Function
获取函数名称
1 | F.getName() |
获取入口块
1 | F.getEntryBlock() |
函数中基本块遍历
1 | for(BasicBloack &BB : F){ |
BasicBlock
获取基本块名称
1 | BB.getName() |
获取基本快终结指令
1 | BB.getTerminator() |
基本块中指令的遍历
1 | for(BasicBloack &BB : F){ |
Instruction
指令中遍历操作数
1 | for(BasicBloack &BB : F){ |
输出流相关
打印日志
outs():一般信息
errs():错误信息
dbgs():调试信息
1 | outs()<<"Function"<<F.getName()<<"\n"; |
6.代码混淆原理

混淆方法
符号混淆
将函数的符号,全局变量名去除或者混淆,elf文件可通过strip指令去除符号表.
控制流混淆
混淆程序的正常控制流,功能不变,而不能清晰反映程序正常逻辑.
控制流平坦化,虚假控制流,随机控制流
计算混淆
混淆程序的计算流程,或计算流程中使用的数据,是分析者难以分析执行的计算.
指令替代,常量替代.
虚拟机混淆
将一组指令集合,转化为分析者未知的自定义指令集,并用与程序绑定的解释器解释执行
VMProtect
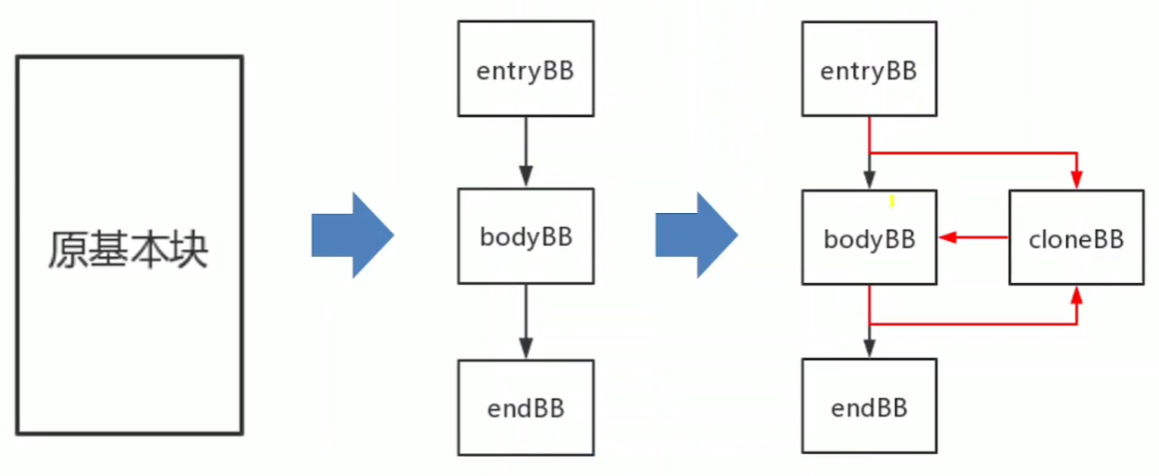
基本块的分割
基本块分割是将一个基本块分割为等价的若干个基本块,在分割后的基本块之间加上无条件跳转.
基于基本块的代码混淆中,基本块数量越多,代码混淆后的复杂度越大.通过增加i基本块的数量,可以提升混淆效果.
遍历每个函数中的每个基本块,对每个基本块进行分割.
PHI指令的基本块目前要跳过,PHI指令的基本块如果分割,前驱块会发生变化,但是是有解决方法的.
控制流平坦化
控制流平坦化是将正常控制流中基本块之间的跳转关系删除,用一个集中的分发块来调度基本块之间的执行顺序.
结构如下
入口块:进入函数第一个执行的基本块
主分发块和子分发块:负责跳转到下一个要执行的基本块.
原基本块:混淆之前的基本块,真正完成程序工作的基本块
返回块:返回到主分发块,进行下一轮基本块的分发.
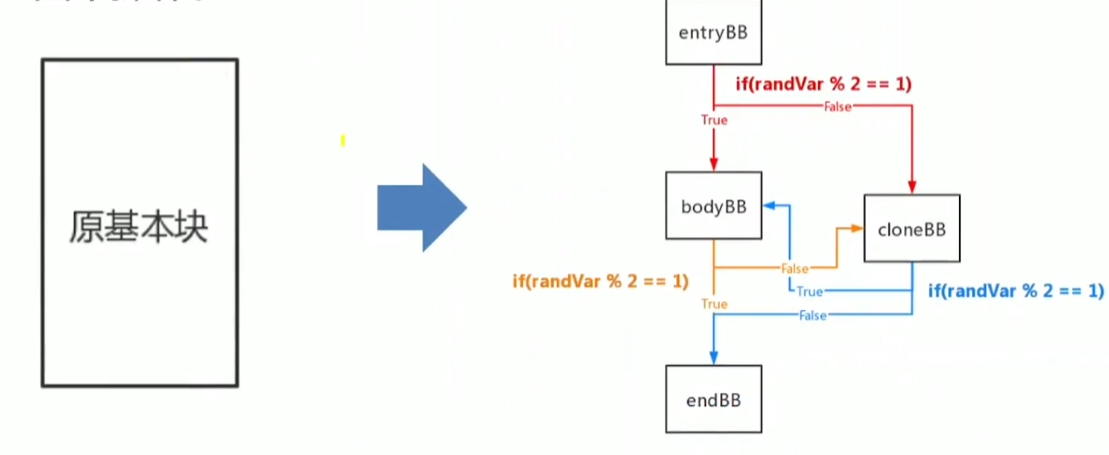
虚假控制流
向正常控制流中插入若干不可达基本块(不会执行的基本块)和由不透明谓词造成的虚假跳转,产生大量无效代码干扰分析.
虚假控制流以基本块为单位进行混淆,每个基本块要经过分裂,克隆,构造虚假跳转操作.
指令替代
将正常的二元运算指令,替换为等效的复杂指令,达到混淆计算过程的目的.
扫描所有指令,对目标指令进行替换,加法减法或非并等等运算.
加法指令的替换方案

减法指令的替换方案

与的替换方案

或的替换方案

异或的替换方案

随机控制流
随机控制流是虚假控制流的变体,随机控制流通过控制基本块,添加随机跳转到两个功能相同的基本块的控制流,来进行混淆.
关于虚假控制流的去除,虚假控制流可以通过编写脚本的方式去除不透明谓词,然后通过符号执行引擎将不可达基本块去除.
通过rdrand指令生成的随机控制,可以干扰angr等符号执行引擎的分析.
实现方法与虚假控制流类似:
基本块要经过分裂,克隆,构造随机跳转,构造虚假随机跳转.
需要注意的一点不同是,随机控制流克隆出来的基本块是可能被执行到的,所以需要对逃逸变量进行修复.
常量替代
常量替代是将二元运算指令中使用的常数替换为更复杂的表达式.达到混淆计算过程的目的.
目前仅支持整数常量的替换,因为替换浮点数会造成误差.
替换方案:
线性替换:val->ax+by+c,a,b为随机常量,x,y为随机全局变量,c=val-(ax+by)
按位运算替换:val->(x<<5|y>>3)^c,x为原常量x,y为随机全局变量 c=val^(x<<5|y>>3)